Spark Architecture : Shuffle
Spark holds data in memory resulting in fast processing, but sometimes due to memory constrains its not possible to hold all the data in one memory block. As a result spark splits the data among different nodes on the cluster. this comes with price, slow processing.
we will divide this topic in below sections
- Why shuffling
- What is shuffling
- Types of shuffling
Why Shuffling
Partitioning
- To distribute work across the cluster and reduce the memory requirements of each node, Spark will split the data into smaller parts called Partitions
- Only one partition is computed per executor thread at a time
- size and quantity of partitions passed to an executor is directly proportional to the time it takes to complete.
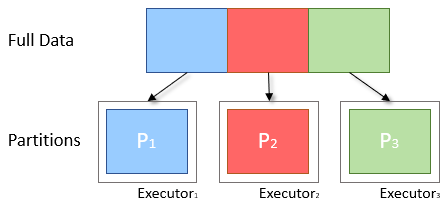
Data Skew
- data is split into partitions based on a key
-
If values are not evenly distributed throughout this key then more data will be placed in one partition than another
{Sandesh, Priyanka, Rudransh, Sachin, Sumit} > S: {Sandesh, Sachin, Sumit} > P: {Priyanka} > R: {Rudransh}
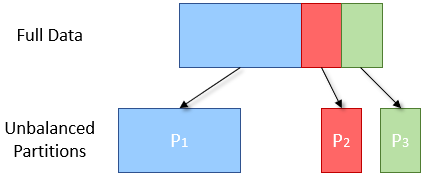
-
Here the partition 1 for key S is three times more than the other two hence it takes more time to compute as compare to other two.
-
next stage of processing cannot begin until all three partitions are evaluated, the overall results from the stage will be delayed.
Scheduling
- sometimes there are too few partitions to correctly cover the number of executors available.
- An example is given in the diagram below, in which there are 2 Executors and 3 partitions.
- Executor 1 has an extra partition to compute and therefore takes twice as long as Executor 2. This results in Executor 2 being idle and unused for half the job time.
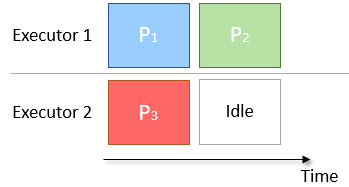
Solution is to increase the number of partition but results in Shuffling
What is Shuffling ?
- A shuffle occurs when data is rearranged between partitions
- when a transformation requires information from other partitions, such as summing all the values in a column.
- Spark will gather the required data from each partition and combine it into a new partition, likely on a different executor.
- During a shuffle, data is written to disk and transferred across the network
- this impacts Spark’s ability to do processing in-memory and causing a performance bottleneck
-
we should try to reduce the number of shuffles being done or reduce the amount of data being shuffled.
- In the shuffle operation, the task that emits the data in the source executor is
mapper - he task that consumes the data into the target executor is
reducer - what happens between them is
shuffle.
Shuffling in general has 2 important compression parameters
spark.shuffle.compress = true // engine would compress shuffle outputs or not
spark.shuffle.spill.compress = true //compress intermediate shuffle spill files or not
spark.io.compression.codec = snappy //default codec (z4, lzf, snappy, and zstd )
spark.shuffle.manager = sort //Three possible options are: hash, sort, tungsten-sort, sort” option is default starting from Spark 1.2.0. before that hash was default
Types of Shuffle (spark.shuffle.manager)
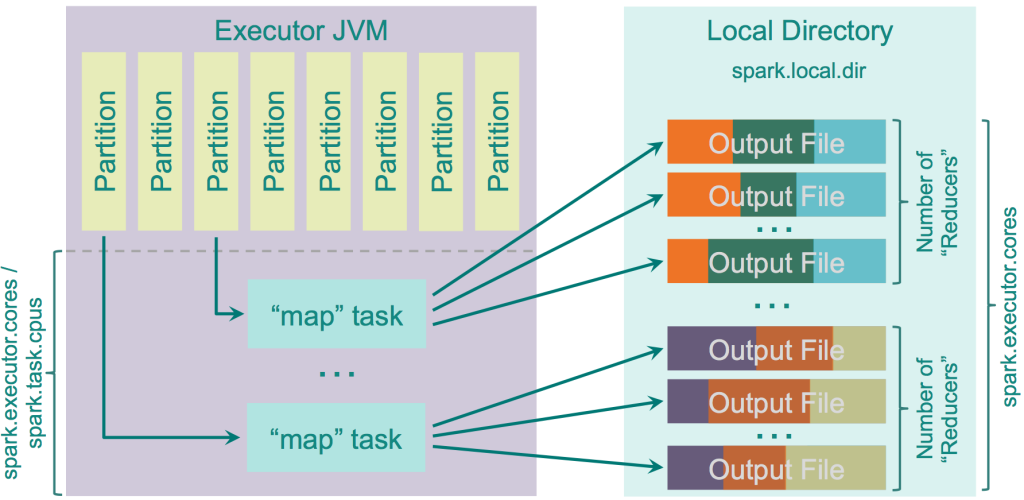
Hash Shuffle
- Prior to Spark 1.2.0 this was the default option of shuffle (spark.shuffle.manager = hash)
- Major drawback is number of output files
-
Each mapper task creates
separate fileforeach separate reducer\Resulting files = M * R M is the number of “mappers” R is the number of “reducers” - For yahoo 6k mappers and 46k reducers generating 2 billion files on the cluster.
Logic:
- calculates the amount of “reducers” as the amount of partitions on the “reduce” side
- creates a separate file for each of them
- loops through the records it needs to output
- calculates target partition for each of them and outputs the record to the corresponding file.
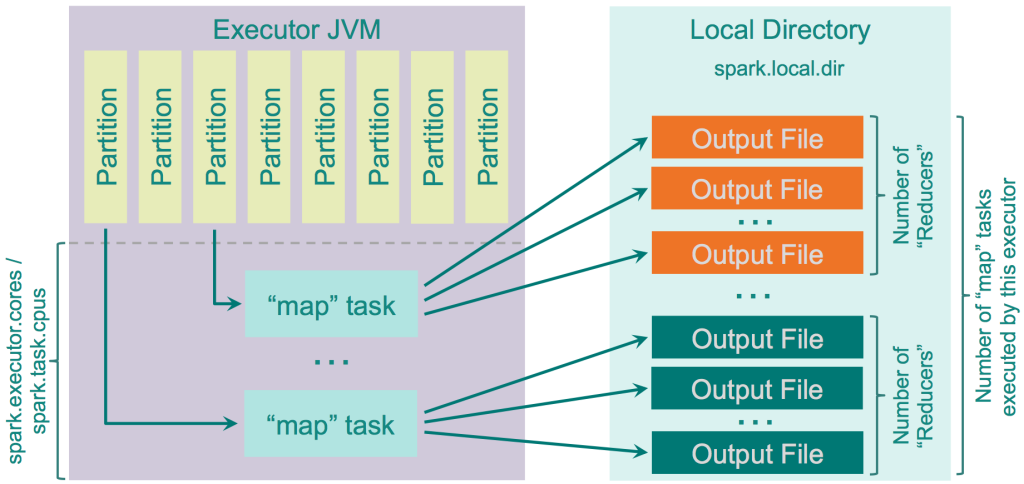
There is an optimization implemented for this shuffler, controlled by the parameter “spark.shuffle.consolidateFiles” (default is “false”). When it is set to “true”, the “mapper” output files would be consolidated.
Pros:
- Fast – no sorting is required at all, no hash table maintained;
- No memory overhead for sorting the data;
- No IO overhead – data is written to HDD exactly once and read exactly once.
Cons:
- When the amount of partitions is big, performance starts to degrade due to big amount of output files
- Big amount of files written to the filesystem causes IO skew towards random IO, which is in general up to 100x slower than sequential IO
spark.reducer.maxSizeInFlight = 48MB (default)
increase this size, your reducers would request the data from “map” task outputs in bigger chunks, which would improve performance//determines the amount of data requested from the remote executors by each reducer. increasing
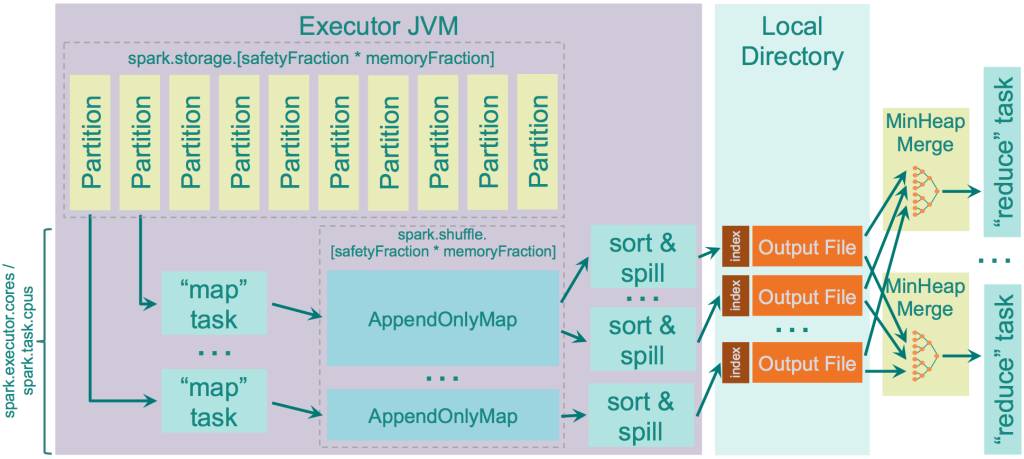
Sort Shuffle (spark.shuffle.manager = sort)
- shuffle logic similar to the one used by Hadoop MapReduce
- output a single file ordered by “reducer” id and indexed
- to get data for “reducer x” get information about the position of related data block in the file and doing a single fseek before fread
- Sorts the data on the “map” side, but does not merge the results of this sort on “reduce” side – in case the ordering of data is needed it just re-sorts the data
- for small amount of “reducers” it is obvious that hashing to separate files would work faster than sorting
- sort shuffle has a
fallback” plan: when the amount of reducersis smaller thanspark.shuffle.sort.bypassMergeThreshold(200 by default) we use the “fallback” plan with hashing the data to separate files and then joining these files together in a single file - if you don’t have enough memory to store the whole “map” output? You might need to spill intermediate data to the disk
spark.shuffle.spill = true //by default spilling is enabled. If you would disable it and there is not enough memory to store the “map” output, you would simply get OOM error
Total Memory for sorting Map = JVM Heap Size * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
JVM Heap Size * 0.2 * 0.8
- Spark use
Tim Sortas sorting Algo on reducer side
Logic
- Spark internally uses AppendOnlyMap structure to store the “map” output data in memory
- Spark uses their own Scala implementation of hash table that uses open hashing and stores both keys and values in the same array using quadratic probing
- As a hash function they use murmur3_32 from Google Guava library, which is MurmurHash3.
-
This hash table allows Spark to apply “combiner” logic -each new value added for existing key is getting through “combine” logic with existing value, and the output of “combine” is stored as the new value.
-
When the spilling occurs, it just calls “sorter” on top of the data stored in this AppendOnlyMap, which executes TimSort on top of it, and this data is getting written to disk.
- Sorted output is written to the disk when the spilling occurs or when there is no more mapper output, i.e. the data is guaranteed to hit the disk
- Each spill file is written to the disk separately, their merging is performed only when the data is requested by “reducer” and the merging is real-time, i.e. it does not call somewhat “on-disk merger” like it happens in Hadoop MapReduce,
- just dynamically collects the data from a number of separate spill files and merges them together using Min Heap implemented by Java PriorityQueue class.
Pros:
Smaller amount of files created on “map” side Smaller amount of random IO operations, mostly sequential writes and reads
Cons:
Sorting is slower than hashing. It might worth tuning the bypassMergeThreshold parameter for your own cluster to find a sweet spot, but in general for most of the clusters it is even too high with its default In case you use SSD drives for the temporary data of Spark shuffles, hash shuffle might work better for you
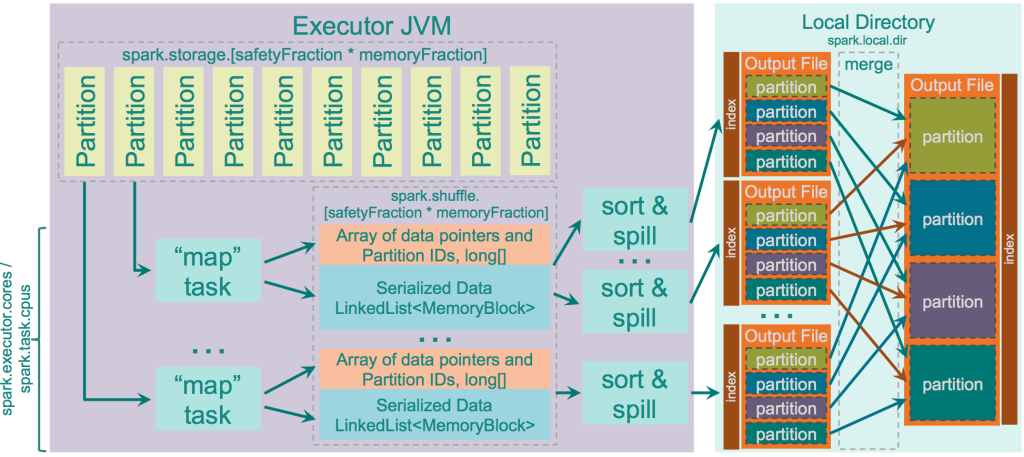
Unsafe Shuffle or Tungsten Sort (spark.shuffle.manager = tungsten-sort)
- This is the part of project
Tungsten.
Logic
- Operate directly on serialized binary data without the need to deserialize it. It uses unsafe (sun.misc.Unsafe) memory copy functions to directly copy the data itself, which works fine for serialized data as in fact it is just a byte array
- Uses special cache-efficient sorter ShuffleExternalSorter that sorts arrays of compressed record pointers and partition ids. By using only 8 bytes of space per record in the sorting array, it works more efficienly with CPU cache
- As the records are not deserialized, spilling of the serialized data is performed directly (no deserialize-compare-serialize-spill logic)
- Extra spill-merging optimizations are automatically applied when the shuffle compression codec supports concatenation of serialized streams (i.e. to merge separate spilled outputs just concatenate them). This is currently supported by Spark’s LZF serializer, and only if fast merging is enabled by parameter “shuffle.unsafe.fastMergeEnabled”
This shuffle implementation would be used only when all of the following conditions hold:
- The shuffle dependency specifies no aggregation. Applying aggregation means the need to store deserialized value to be able to aggregate new incoming values to it. This way you lose the main advantage of this shuffle with its operations on serialized data
- The shuffle serializer supports relocation of serialized values (this is currently supported by KryoSerializer and Spark SQL’s custom serializer)
- The shuffle produces less than 16777216 output partitions
- No individual record is larger than 128 MB in serialized form
Pros:
Many performance optimizations described above
Cons:
Not yet handling data ordering on mapper side Not yet offer off-heap sorting buffer Not yet stable