Memory Management
Tasks are the basically the threads that run within the Executor JVM of a Worker node to do the needed computation. It is the smallest unit of execution that operates on a partition in our dataset. Given that Spark is an in-memory processing engine where all of the computation that a task does happens in-memory, its important to understand Task Memory Management...
To understand this topic better, we’ll section Task Memory Management into 3 parts:
- What are the memory needs of a task?
- Memory Management within a Task
- Memory Management across the Tasks
1. What are the memory needs of a task?
Every task needs 2 kinds of memory:
- Execution Memory:
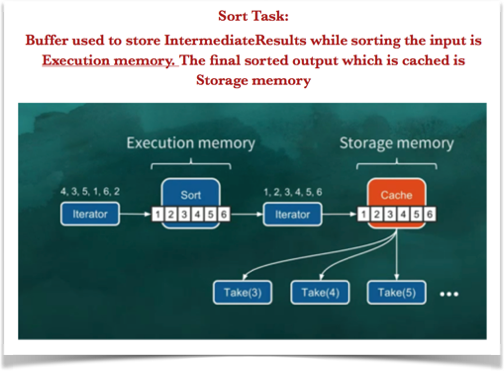
- Execution Memory is the memory used to buffer Intermediate results.
- As soon as we are done with the operation, we can go ahead and release it. Its short lived.
- For example, a task performing Sort operation, would need some sort of collection to store the Intermediate sorted values.
- Storage Memory:
- Storage memory is more about reusing the data for future computation.
- This is where we store cached data and its long-lived.
- Until the allotted storage gets filled, Storage memory stays in place.
- LRU eviction is used to spill the storage data when it gets filled.
Following picture illustrates it with an example task of “Sorting a collection of Int’s”
Now that we’ve seen the memory needs of a task, Let’s understand how Spark manages it..
2. Memory Management within a Task
How does Spark arbitrate between ExecutionMemory(EM) and StorageMemory(SM) within a Task?
Simplest Solution – Static Assignment
- Static Assignment - This approach basically splits the total available on-heap memory (size of your JVM) into 2 parts, one for ExecutionMemory and the other for StorageMemory.
- As the name says, this memory split is static and doesn’t change dynamically.
- This has been the solution since spark 1.0.
- While running our task, if the execution memory gets filled, it’ll get spilled to disk as shown below:
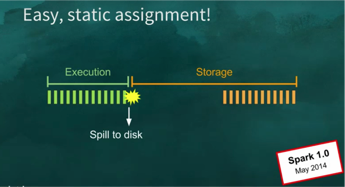
- Likewise, if the Storage memory gets filled, its evicted via LRU (Least recently Used)

Disadvantage: Because of the hard split of memory between Execution and Storage, even if the task doesn’t need any StorageMemory, ExecutionMemory will still be using only its chunk of the total available free memory..

How to fix this?
UNIFIED MEMORY MANAGEMENT - This is how Unified Memory Management works:
- Express execution and storage memory as one single unified region.
- So, there’s no splitting of memory in this approach.
- Execution and Storage share it combinedly with this agreement:
Keep acquiring execution memory and evict storage as u need more execution memory.
Following picture depicts Unified memory management..

But, why to evict storage than execution memory?
Spilled execution data is always going to be read back from disk where as cached data may or may not be read back. (User might tend to aggressively cache data at times with/without its need.. )
What if application relies on caching like a Machine Learning application?
We can’t just blow away cached data like that in this case. So, for this usecase, spark allows user to specify minimal unevictable amount of storage a.k.a cache data. Notice this is not a reservation meaning, we don’t pre-allocate a chunk of storage for cache data such that execution cannot borrow from it. Rather, only when there’s cached data this value comes into effect..
3.Memory Management across the Tasks
How is memory shared among different tasks running on the same worker node?
Ans: Static Assignment (again!!) - No matter how many tasks are currently running, if the worker machine has 4 cores, we’ll have 4 fixed slots.
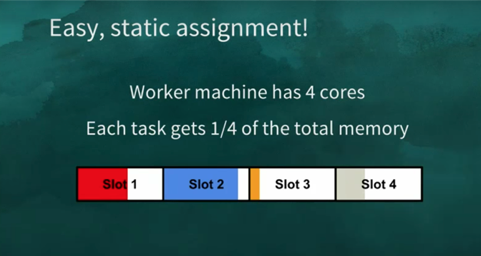
Drawback: Even if there’s only 1 task running, its going to get only one-quarter of the total memory.
Better Solution – Dynamic Assignment (Again)!!
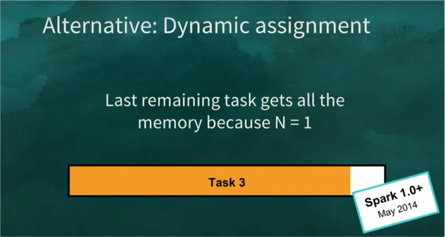
More efficient alternative is Dynamic allocation where how much memory a task gets is dependent on total number of tasks running. If there is only one task running, it can feel free to acquire all the available memory.

As soon as another task comes in, task1 will have to spill to disk and free space for task2 for fairness. So, number of slots are determined dynamically depending on active running tasks.

Key Advantage: One notable behaviour here is - What happens to a straggler which is a last remaining task. These straggler tasks are potentially expensive because everybody is already done but then this is the last remaining task. This model allocates all the memory to the straggler because number of actively running tasks is one. This has been there since spark 1.0 and its been working fine since then. So, Spark haven’t found a reason to change it.
CONCLUSION - TASK MEMORY MANAGEMENT
We understood:
- Two kinds of memory needs per task
- How to arbitrate within a task (i.e., between execution and storage memory of a single task)
- How to arbitrate memory between multiple tasks
- Common Solution: Instead of statically reserving memory, force memory to spill when there’s memory contention. So, essentially, solve memory contention lazily rather than eagerly.
- Static assignment is simpler
- Dynamic allocation handles stragglers better